连接完数据源后,便可以将需要的多张数据表关联成一张宽表,并进行需要的数据处理(如字段重命名、新建计算字段、创建层级、调整字段顺序等操作),建立数据模型以便于进行后续的数据可视化分析工作。
新建数据模型
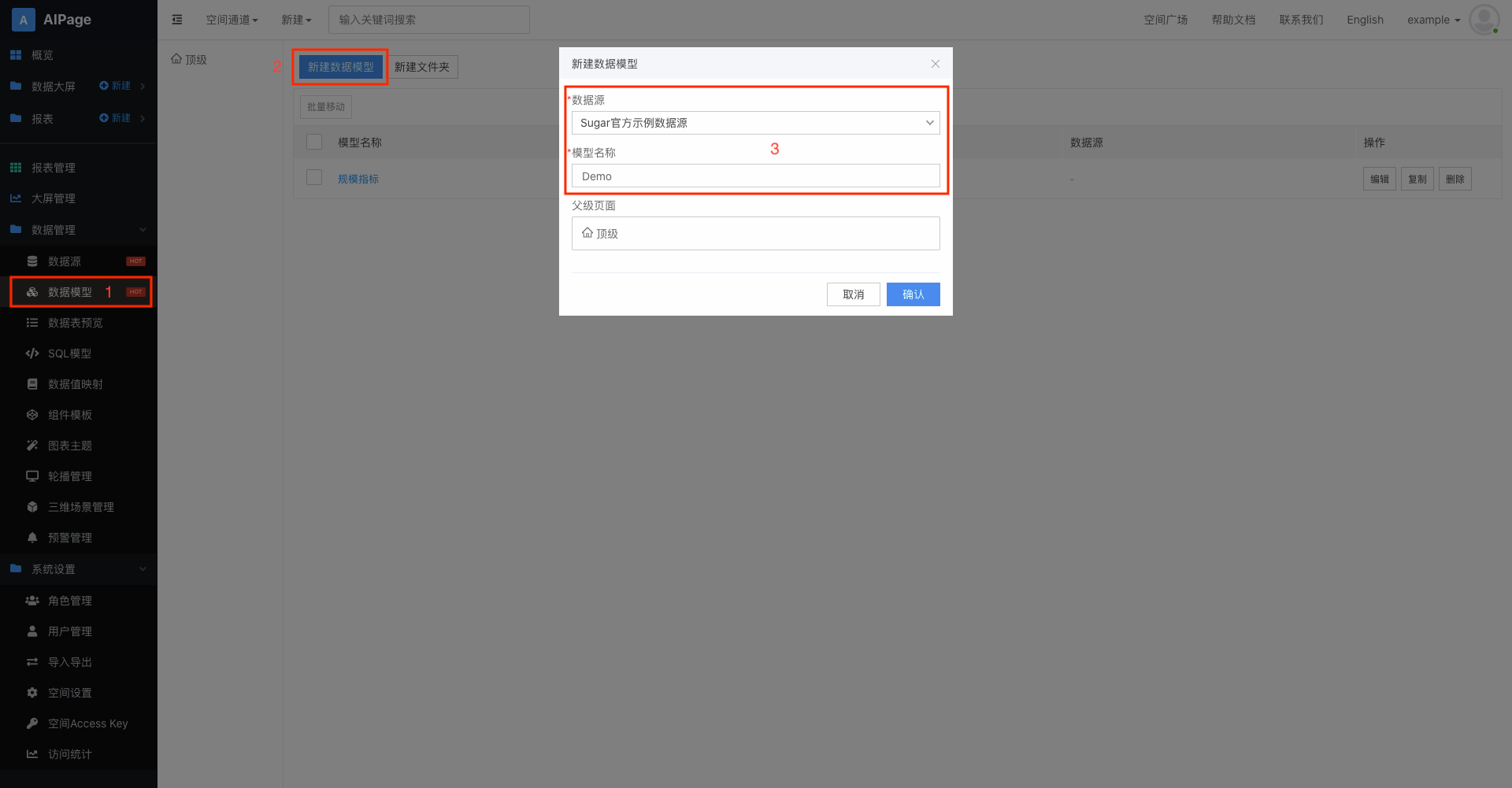
在空间中的「数据模型」页面即可创建数据模型,选择需要连接的数据源,输入数据模型名称即可:
在「数据模型」页面中也可对空间中的所有模型做管理操作,如:创建文件夹、移动模型到指定的文件夹中、对数据模型做排序等。
添加数据表
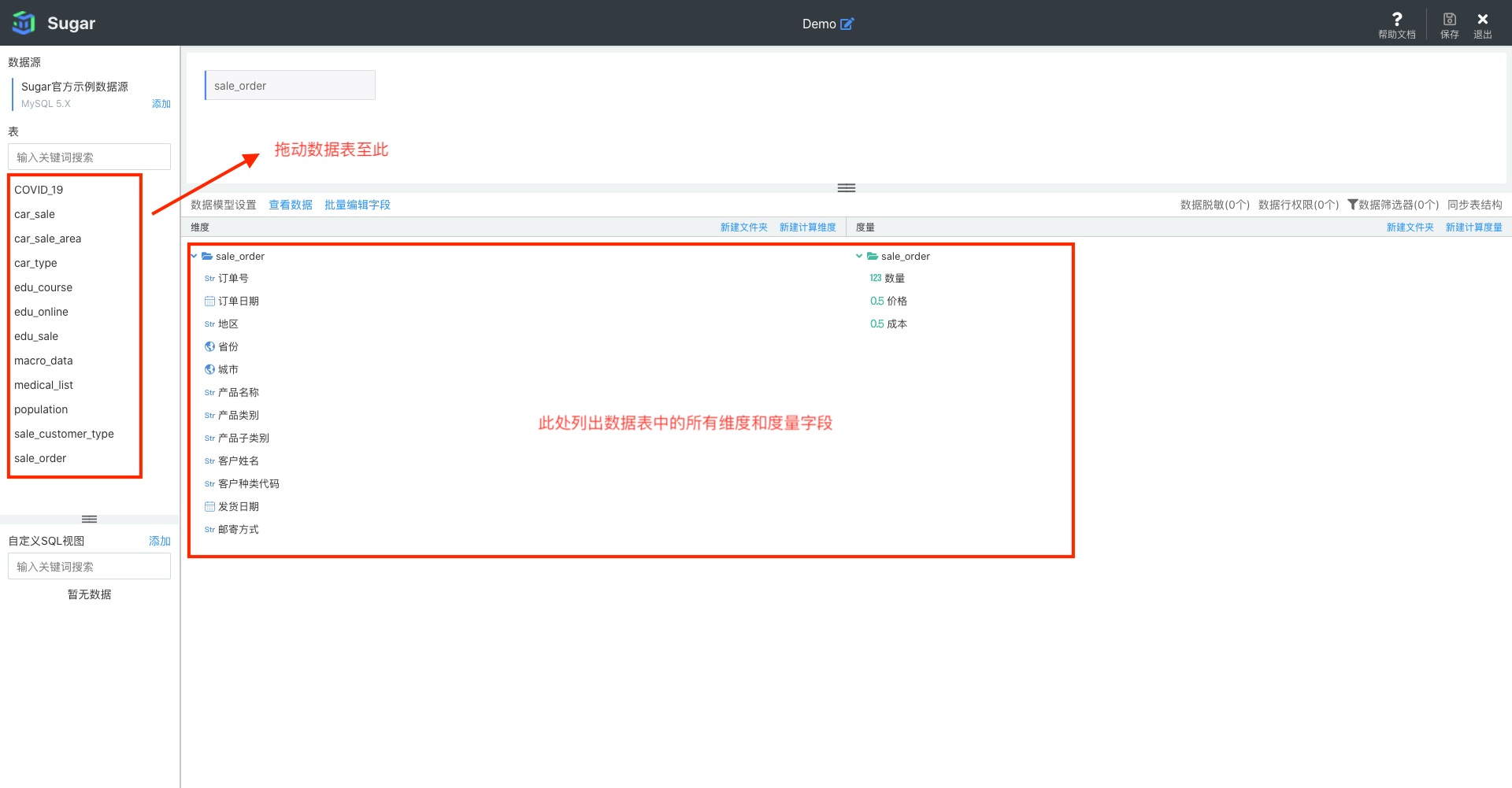
上一步新建了数据模型后即会进入到模型的编辑页面,页面的左侧会列出数据源中的所有数据表,拖动要分析的数据表至页面中间区域:
多表关联
当拖入多张数据表时,即可实现多表的关联分析(对应为 SQL 语句中的多表 Join)。多表关联时需要选定两个表关联的字段以及关联的类型(目前支持内连接(inner join)、左连接(left join)和全连接(full join)):
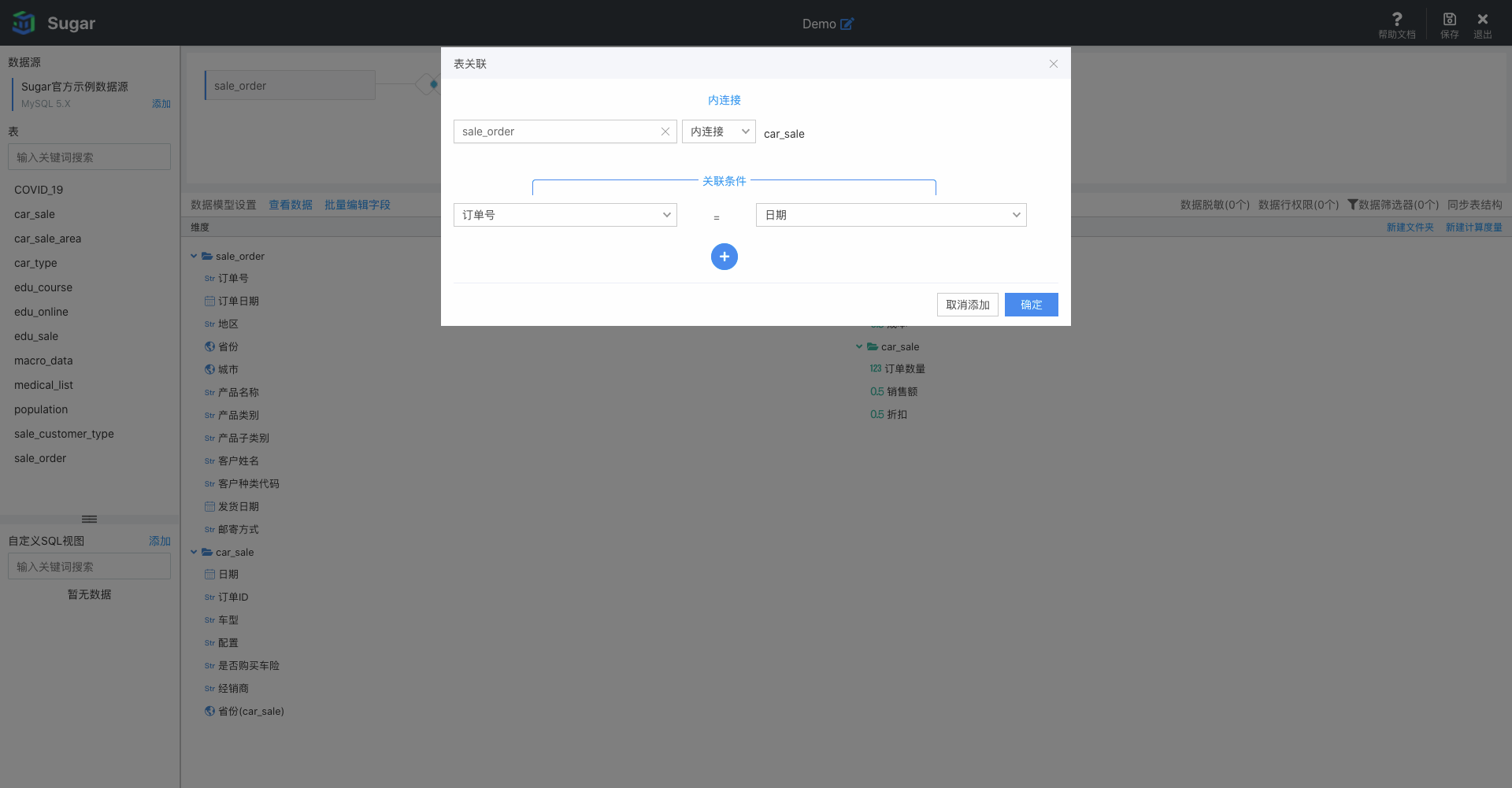
两个表设置关联之后,维度和度量就会分文件夹的方式列出,每个维度和度量以及文件夹都可以鼠标「右键」进行增删改等多种操作,也可拖拽进行顺序的调整或者隐藏一些在分析中用不到的字段等:
维度和度量是什么
维度:分析数据时的粒度
度量:指标的聚合汇总值
聚合方式:汇总的方式,如求和、均值、最大值、最小值
例如我们的官方示例数据源中的销售订单数据(sale_order):
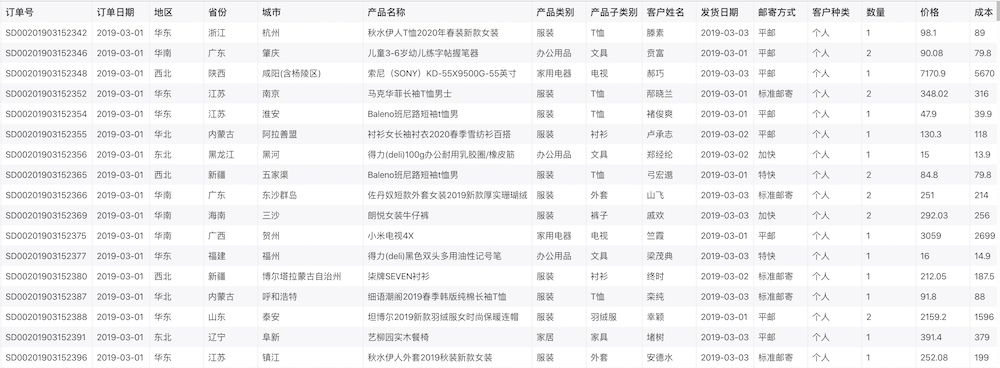
比如我们分析「各个地区的销售价格」,「地区」就是维度,「价格」就是度量,每个地区都有成百上千行数据,我们对这些数据进行了求和汇总。如下图所示:
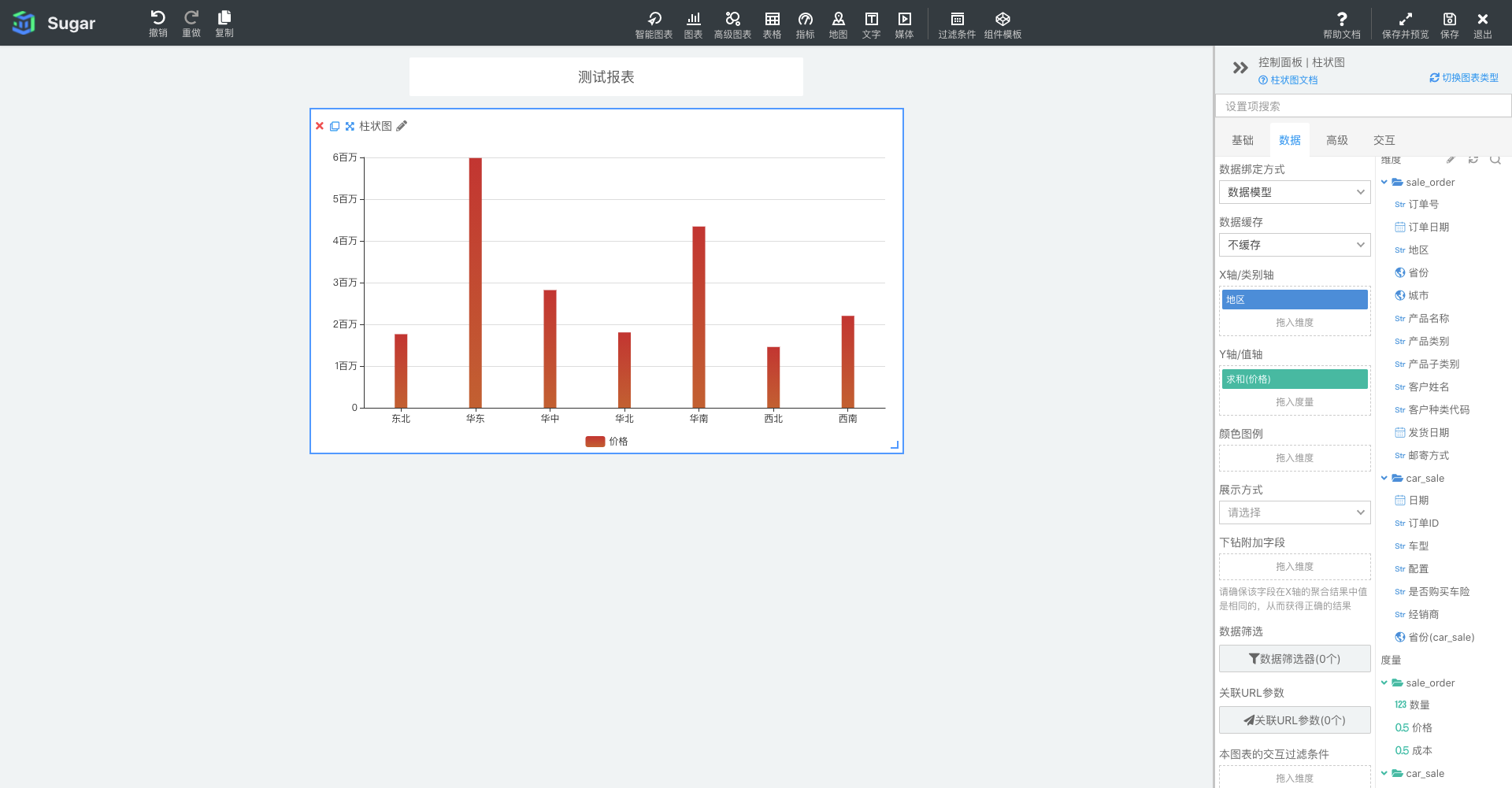
Sugar BI 默认会把字符型的字段归类为维度,数值型的字段归类为度量,用户也可以手动更改字段的类型。
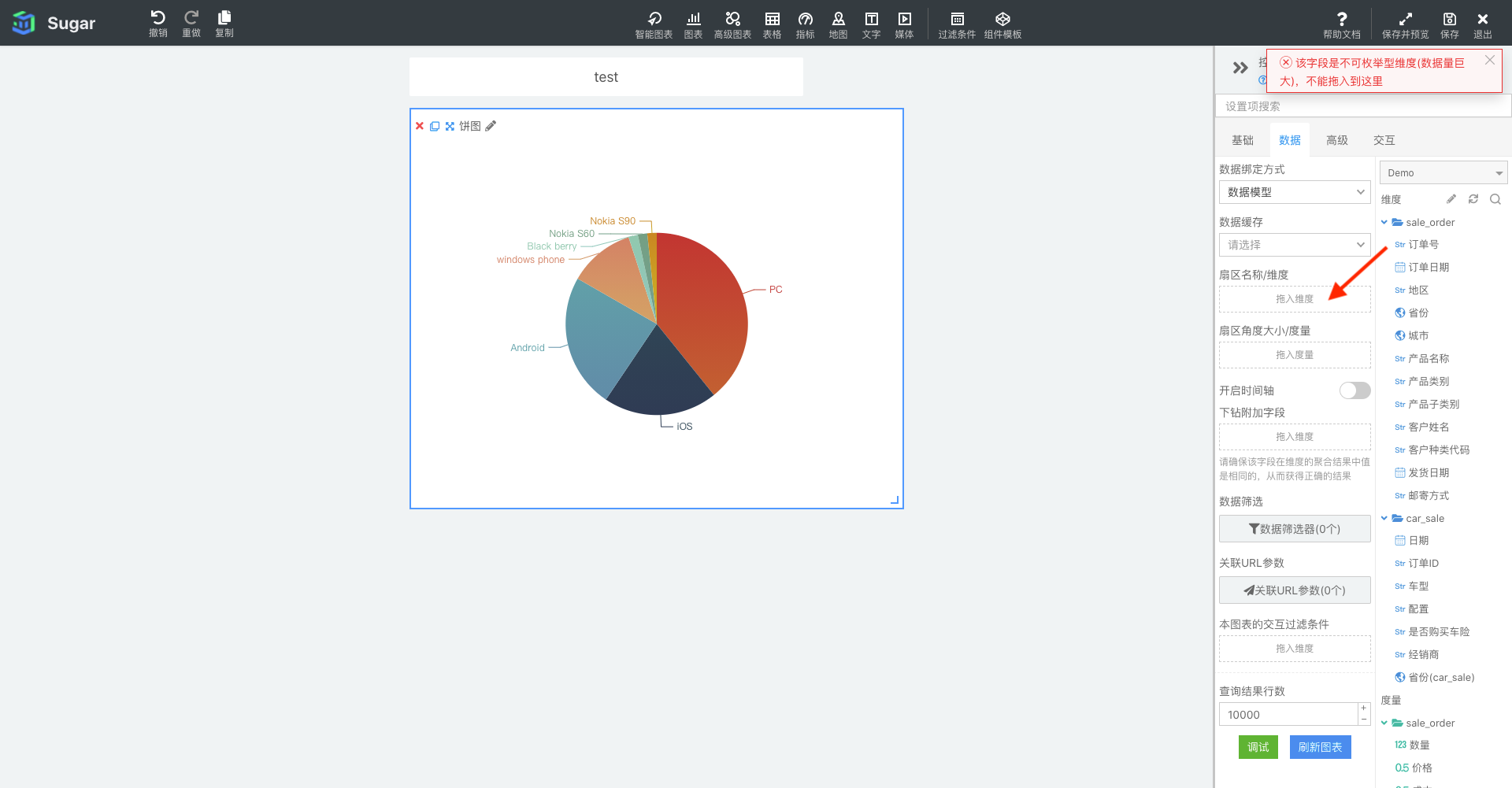
不可枚举型维度
如果某一个字段是不可枚举型的,例如id、用户名等,这类维度字段的取值个数是不可控的,并且是海量的,可设置为不可枚举型字段,如:
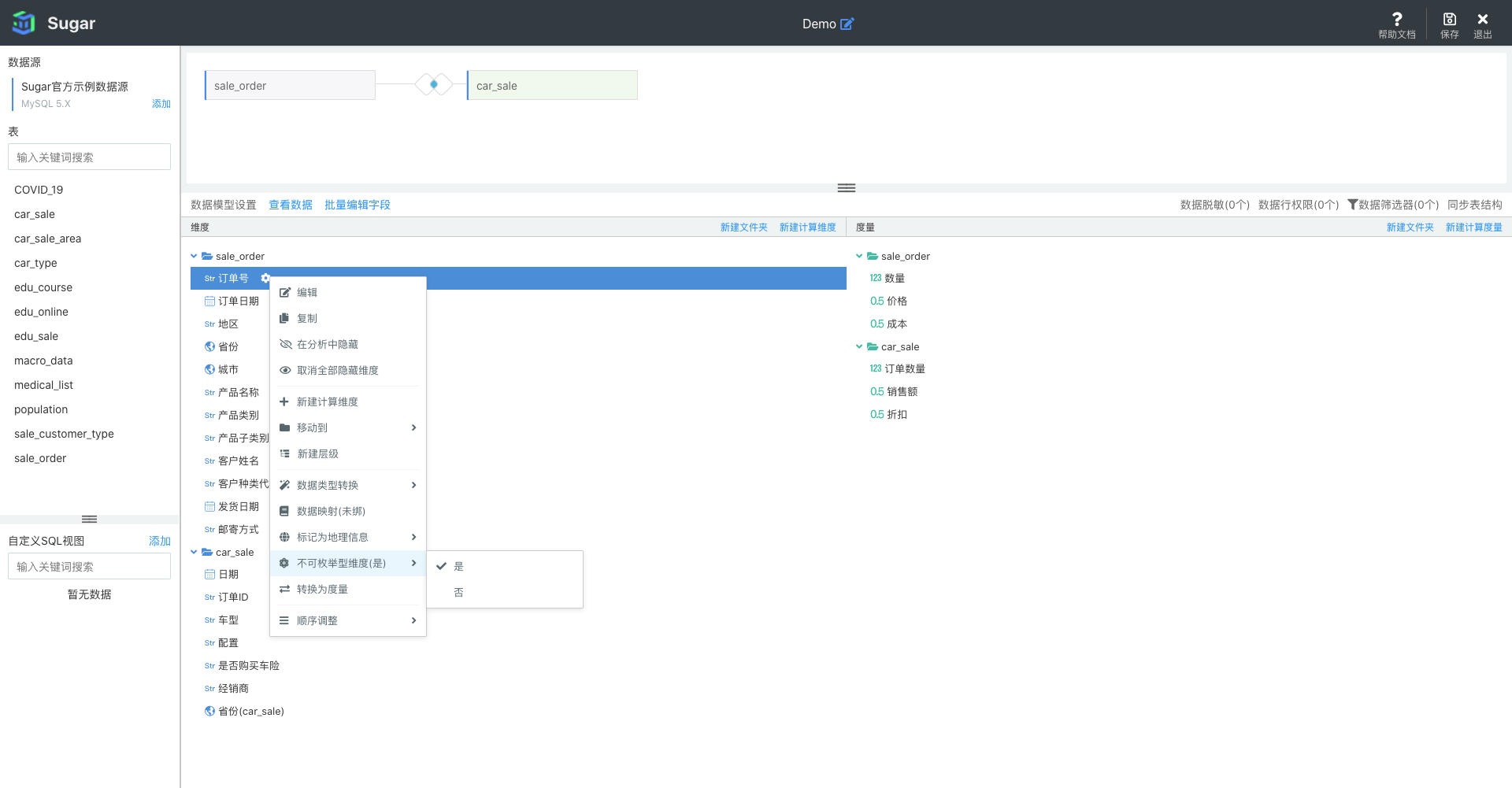
如上设置后,在进行可视化分析时,有些地方就不可拖入这类字段,如饼图的「扇区名称」就不能拖入不可枚举型的维度:
自定义 SQL 视图
Sugar BI的数据模型中支持书写 SQL 语句来创建自定义 SQL 视图,详见自定义 SQL 视图
计算字段
Sugar BI的数据模型中支持以下多种计算字段,详见计算字段
数据类型转换
Sugar BI 中支持转换字段的数据类,例如将字符串类型的 20200108 转换成标准化的日期类型,详见数据类型转换
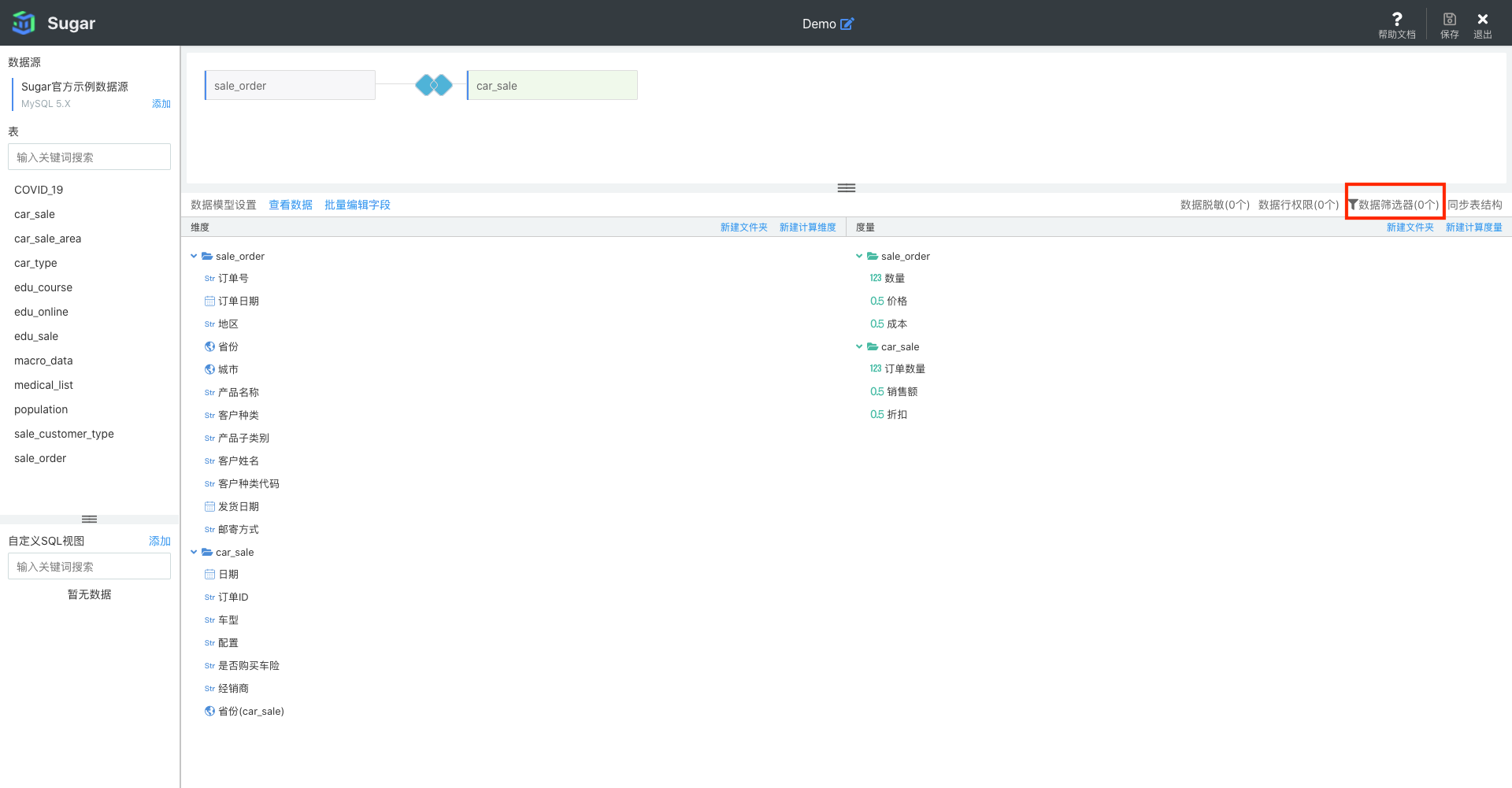
数据筛选
在创建数据模型时,例如我们想让这个数据模型之后只用来分析「东北」地区的数据,而不关心其它地区的数据。此时就可以对该模型设置「数据筛选器」:
点击上图中的「数据筛选器」,并新增一个筛选器,对「地区」字段做限制,只勾选上「东北」
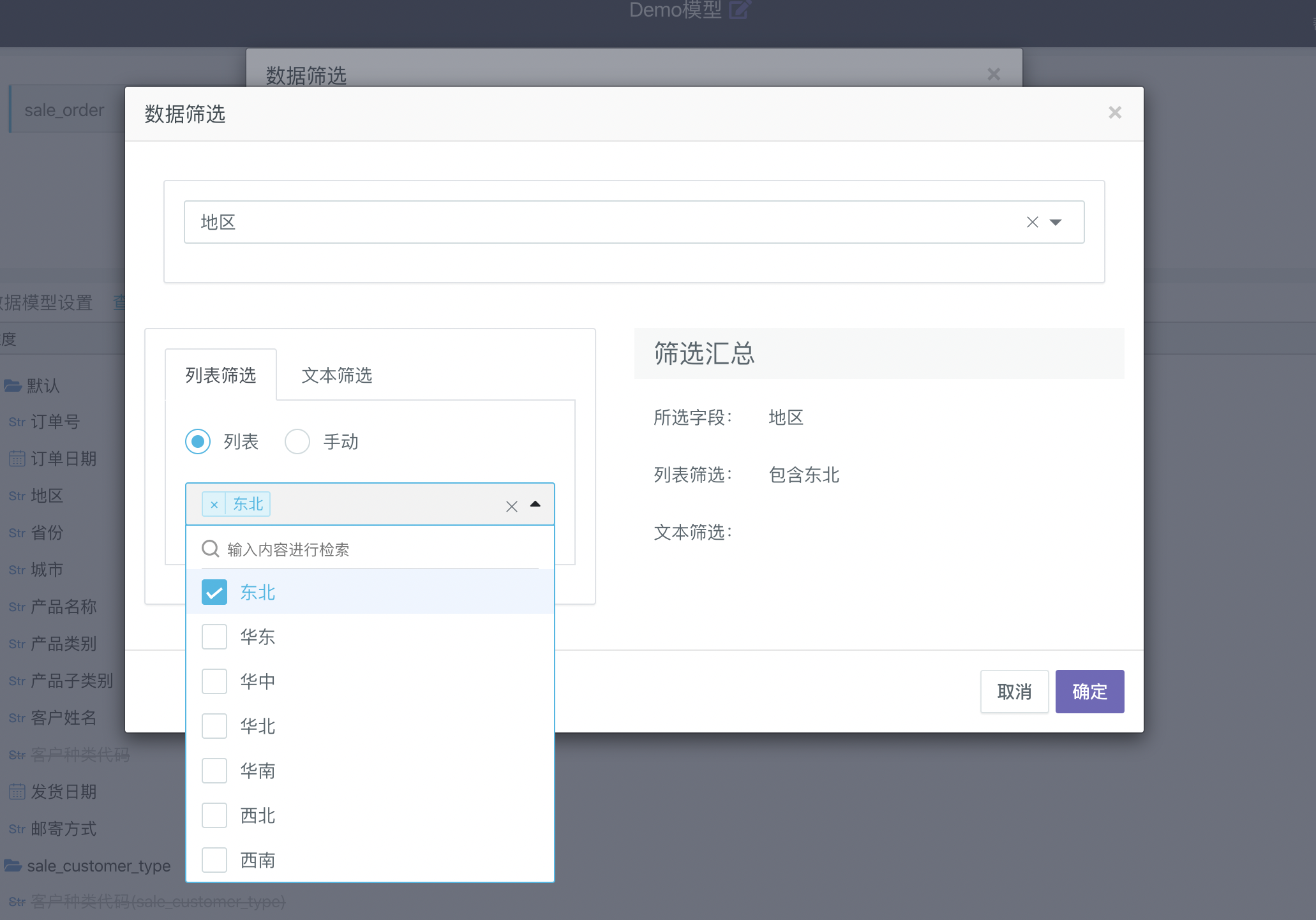
加上该筛选器之后,点击页面中间的「查询数据」,即只能看到「东北」地区的数据,之后基于该数据模型的数据可视化分析也都将只能查询到「东北」地区的数据。
更多关于数据筛选器的描述详见数据筛选。
数据合并 union、union all
Sugar BI 中支持通过自定义 SQL 视图合并结果集,例如:假设我们有两个表:table1 和 table2,它们包含相同的列 column1 和 column2,现在我们想将 table1 和 table2 做合并查询。详见自定义 SQL 视图
行级别权限
如果我们想要实现不同的人使用同一份报表或大屏时,可以看到不同的数据。例如:广东省的员工只能看到广东省的数据,北京市的员工只能看到北京市的数据,可以对该模型进行「数据行权限设置」:
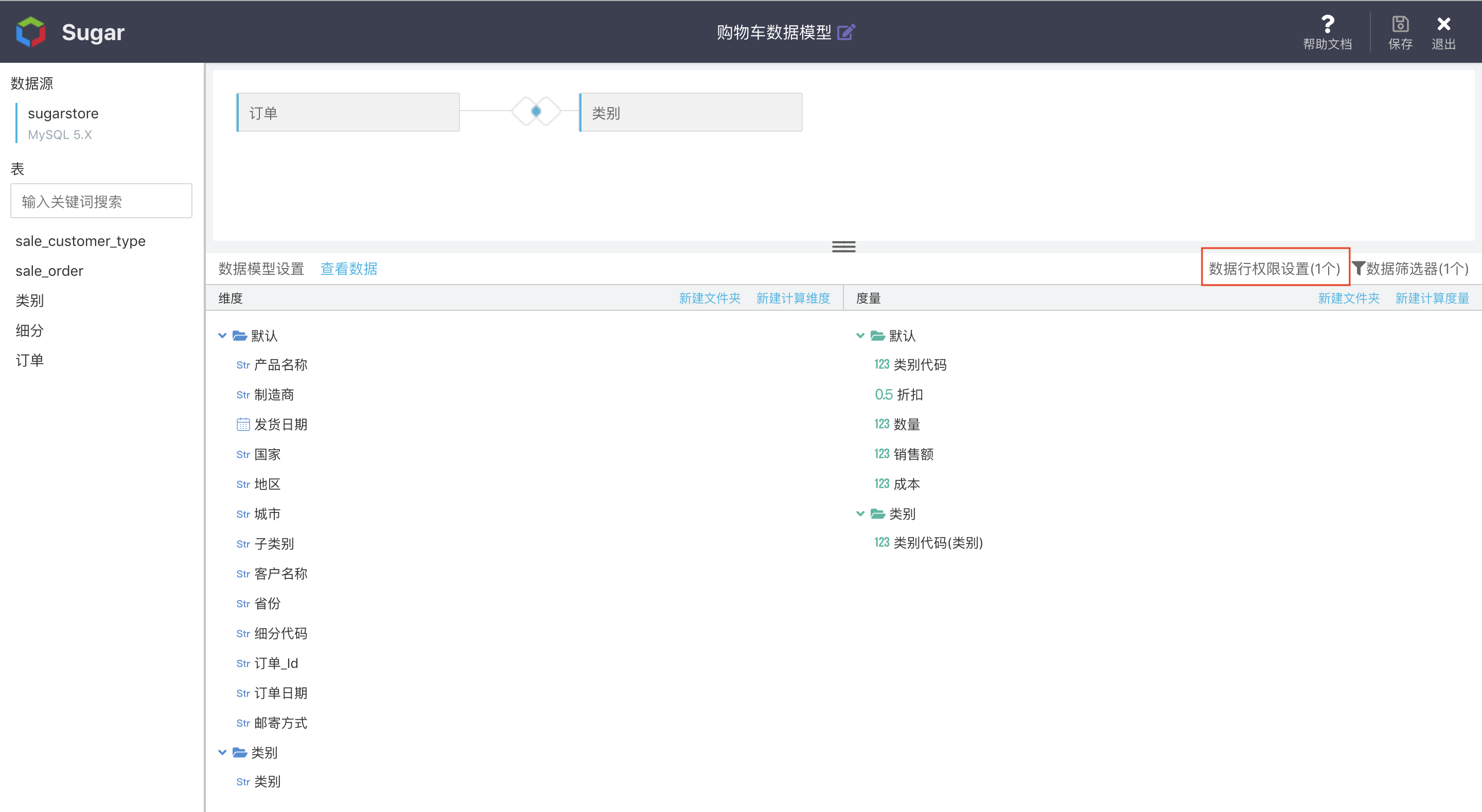
更多关于行级别权限的描述详见行级别权限管理
同步表结构
在报表制作中如遇到源表字段变化的情况,可以通过同步表结构功能进行设置,举例说明: 在下图中源表为 students,其中有四个字段 id、class_id、average 和 age。创建数据集:
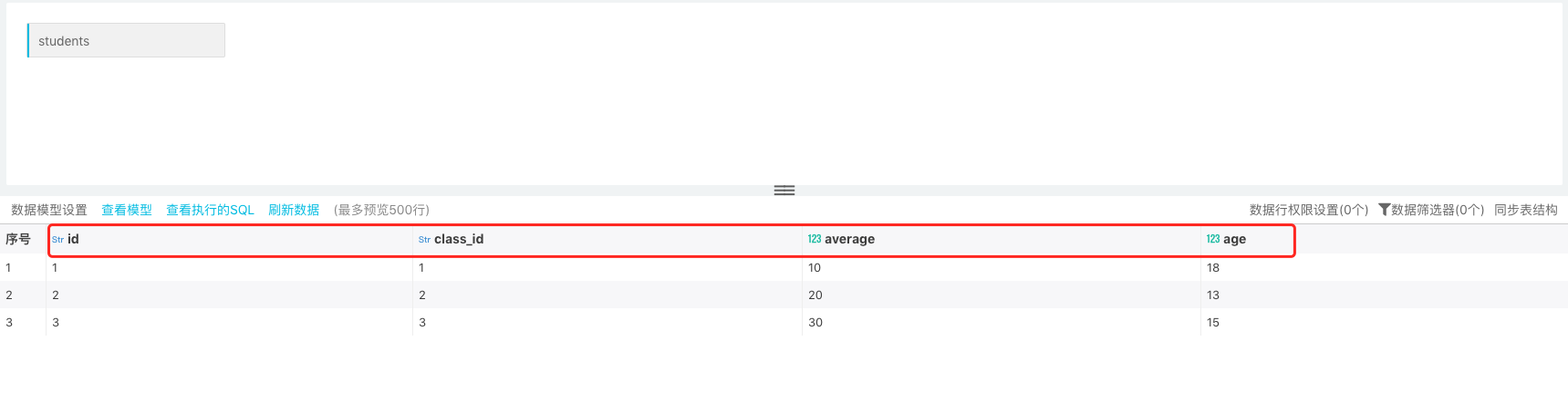
但是后期源表中添加了字段 gender 和 class ,此时只需对原有数据集同步表结构将新添加字段同步过来:
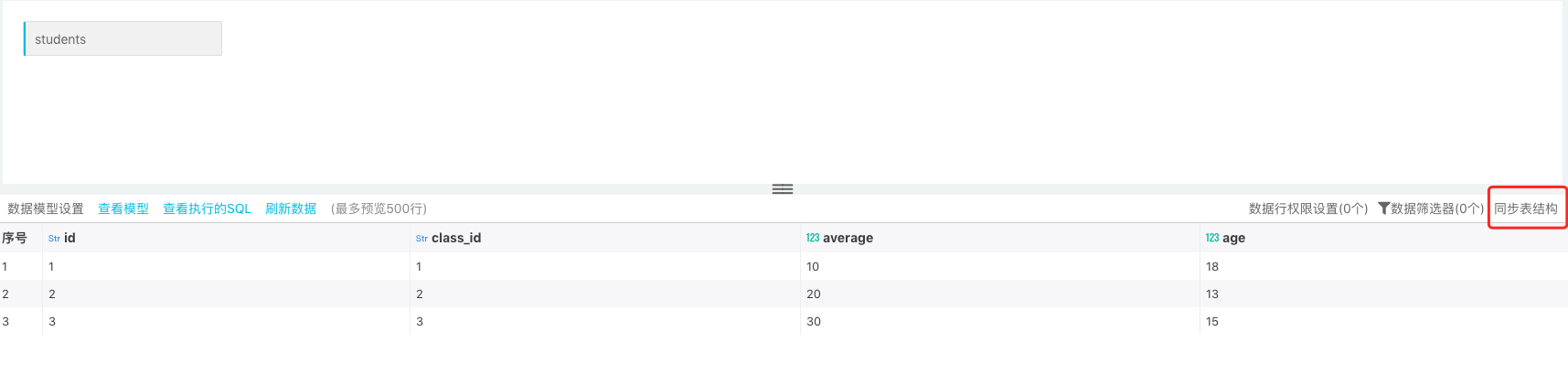
同步表结构后 -> 刷新数据,此时就可以将数据表中新增字段和数据同步过来:
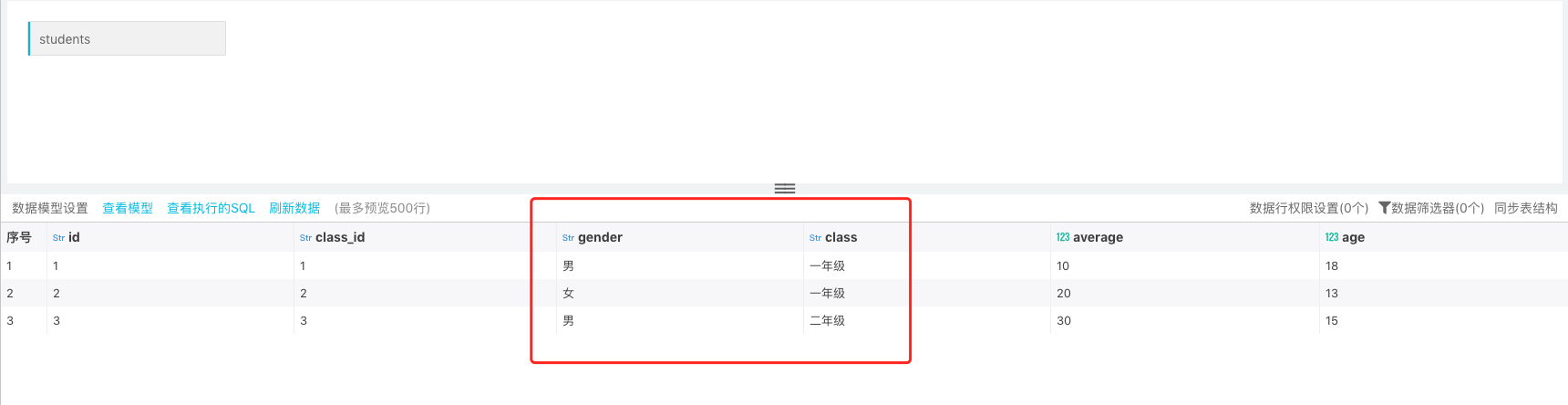
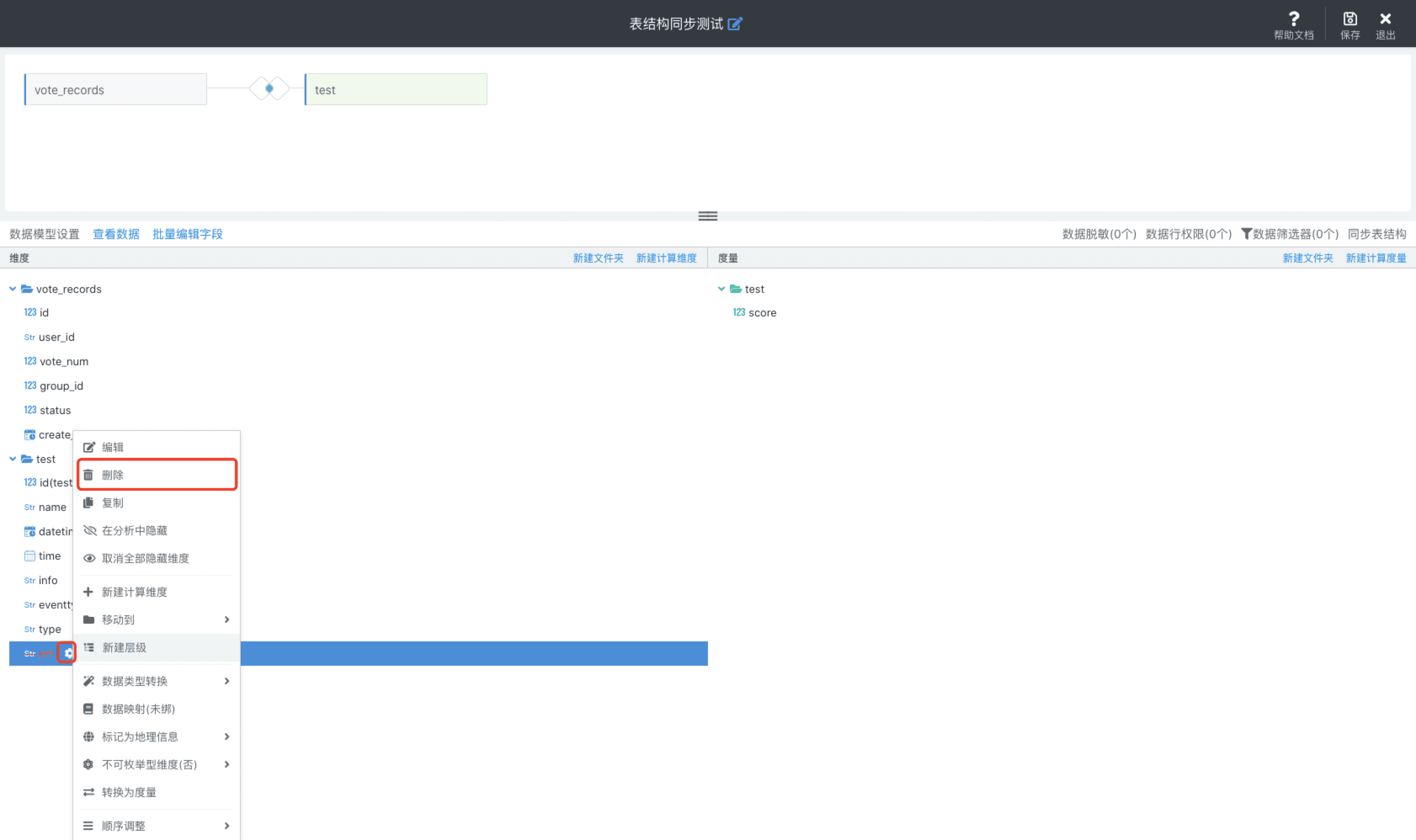
同步表结构也支持删除字段,如果表中有字段被删除,点击同步表结构后会对删除字段进行标记,之后可以在页面中将标记的字段进行删除
如「test」表中有以下字段:
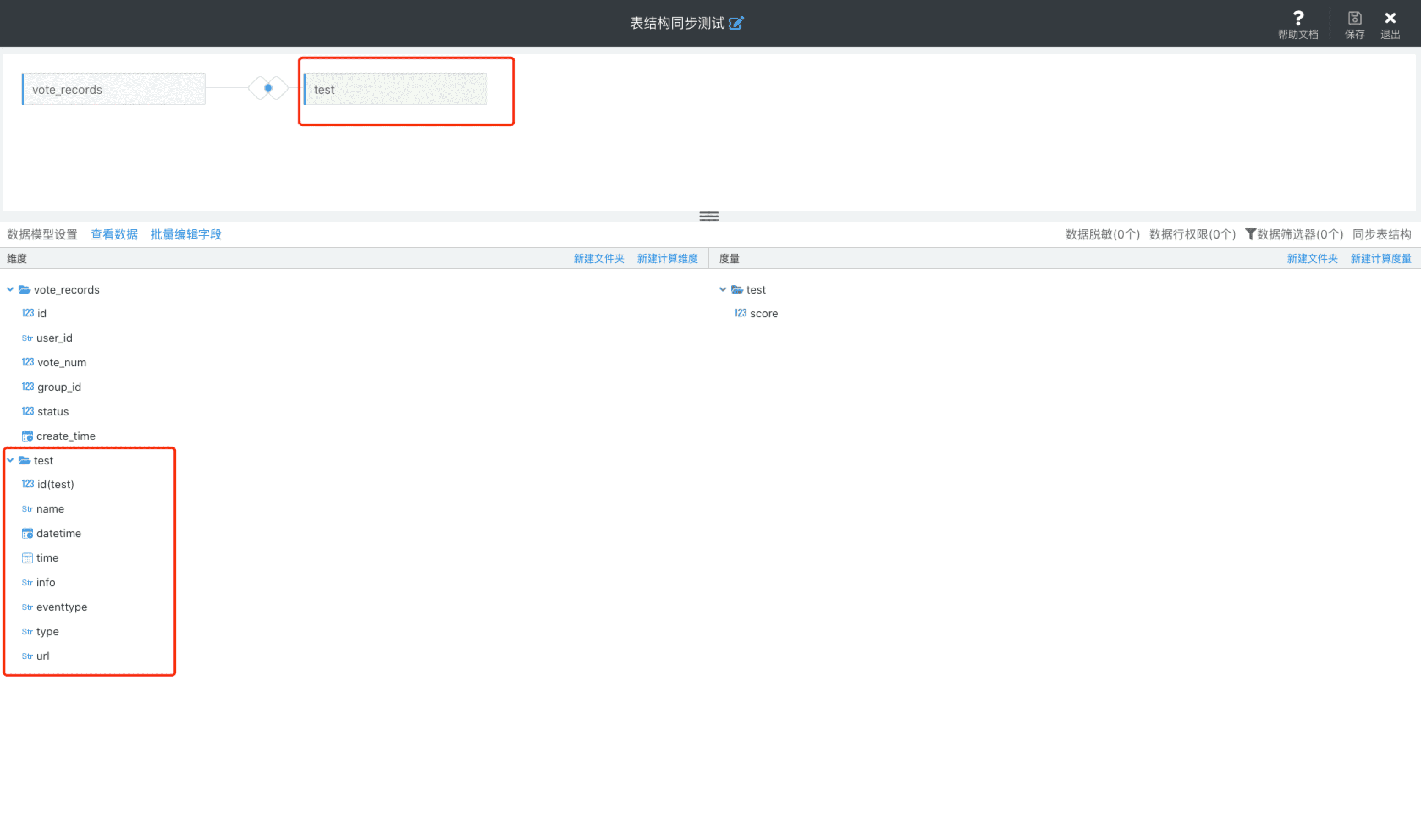
之后将「test」表中的「url」字段删除,此时我们点击「同步表结构」,此时会将删除的字段「url」在前端页面进行删除标识(此时字段信息还未从Sugar BI的 schema 信息中删除):
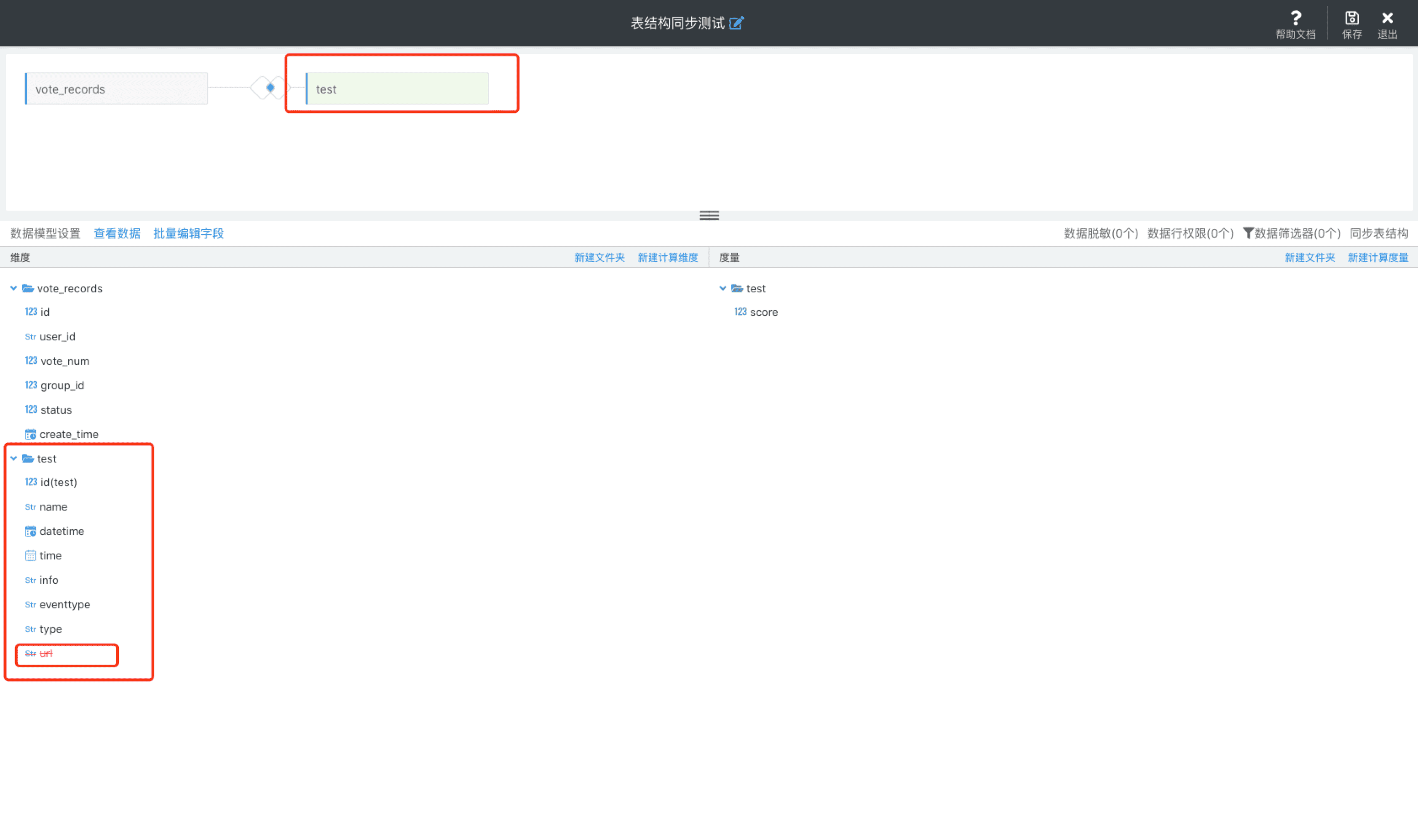
然后我们可以通过「url」字段「设置」->「删除」将该字段从数据模型中删除